STEP 1.1 3種類の探索を比較しよう
<背景解説>
1. 3つの探索とグラフ
- 探索対象の木 分岐数b 深さm
- 資料にある例 b=2, m=3のとき、深さ優先探索、幅優先探索、反復深化探索を、なぞろう。どのノードからどう探索するだろう。
- 深さ優先探索と反復深化探索は、右優先になることの注意 ノード0から、ノード1とノード2を探索管理用スタックのPUSHするので、2からPOPされる。
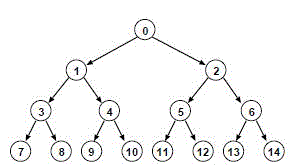
- 探索頂点(目標状態) g
- 同じ深さ d のとき、各探索方法で、どちらの端が最良/最悪になるかを確認すること。
- 3つのアルゴリズムを比較するときは、同じ深さ d のゴールについて最悪となる頂点g を比較すること。
2. 3つの探索アルゴリズムを比較する
- 時間計算量は、whileループの回数。OPENリストを出力しているので、行数が指標になる
- 空間計算量は、OPENリストの最悪の状態。リストの長さ、中でも最悪の長さにあたる、最大長。
b, m, d (ゴールの深さ)と3つのアルゴリズム
- b (木の分岐数)の効果を比較したいなら、m (木の深さ) と d (ゴールの深さ)は固定 (bだけを変化させて、それぞれの探索の時間計算量と空間計算量を比較)
- 同様に、m(深さ)の効果を比較したいなら、b, dを固定
<3つの探索を比較するための作業を考えよう>
1. 同じ d の、左端と右端の頂点のID を計算したい
(node.cをコンパイルして作ったコマンド nodeを使おう)
- 枝の数bのとき、各段の左端と右端のノード番号を得る。 (このプログラムは面倒。両端だけをプリントするプログラムを配布。 node.c)
0 : 0
1: 1 ~ b
2: b+1 ~ b+b**2
3: b+b**2+1 ~
b+b**2+b**3
4: b+b**2+b***3+1 ~ b+b**2+b***3+b****4
- たとえば、b = 2 m = 3のときは、15ノード。0から始まるので、14まで。
1.1 一度に、いくつも調べたい
- ファイルの各行にコマンドを書いて、まとめて1つのコマンドにしてしまう。このようなお手軽ファイルコマンドを、シェルスクリプトという。
- では、nodes.shというファイル名で、下のような内容のファイルを作ろう
- bの値を変えて、m=4, d=4の計算結果を出力させる。
#!/bin/sh
./node 2 4 4
./node 4 4 4
./node 6 4 4
./node 8 4 4
./node 10 4 4
- パーミッションを変えよう。
- 実行して!
- ディスプレイ出力をファイルに残そう ( > は、リダイレクト)
- ./nodes.sh > b-node
- cat b-node
一番最初の#! の部分を、シェバンという。その行から下を、/bin/shというプログラムで動かせ、と読みます。shは、一番小さなシェルのこと。
2.mt-searchコマンドの処理結果について、数えたい!
./mt-search 2 3 4 0
-> [0] -> NULL
-> [2] -> [1] -> NULL
-> [6] -> [5] -> [1] -> NULL
-> [14] -> [13] -> [5] -> [1] -> NULL
-> [13] -> [5] -> [1] -> NULL
-> [5] -> [1] -> NULL
-> [12] -> [11] -> [1] -> NULL
-> [11] -> [1] -> NULL
-> [1] -> NULL
-> [4] -> [3] -> NULL
Path 2 : -> [4] -> [1] -> [0] .
この結果を何とかできないだろうか (IDSの場合は、出力が異なる。./mt-search 2 3 4 2も試そう)
時間計算量 : ループ数。最後のPathの行を除く行数をカウントできれば:
空間計算量 : 対象の行の[ ] の数を数えて、最大値を求められれば:
こういうときは、ライトウェイトプログラミング言語で、プログラムを書こう!
ヒント: count.py というPythonのプログラムを作ろう。下は、一行読んでは、プリントするだけのプログラム
import fileinput
for line in fileinput.input():
print(line)
実行: mt-searchの出力を python count.py へ、| でつなげば
[tsuchiya@www1 c]$ ./mt-search 2 3 4 0 | python count.py
-> [0] -> NULL
-> [2] -> [1] -> NULL
-> [6] -> [5] -> [1] -> NULL
-> [14] -> [13] -> [5] -> [1] -> NULL
-> [13] -> [5] -> [1] -> NULL
-> [5] -> [1] -> NULL
-> [12] -> [11] -> [1] -> NULL
-> [11] -> [1] -> NULL
-> [1] -> NULL
-> [4] -> [3] -> NULL
Path 2 : -> [4] -> [1] -> [0] .
さらにヒント: 正規表現を使おう。import re。 各行をどうすればよいだろう。ぜひ、自作してみてほしい。
完成したら実行例:
[tsuchiya@www1 c]$ ./mt-search 2 3 4 0 | python count.py
10 4
count.pyのプログラム例は、一番下にあります。
3. | でつないで実行しているコマンドを、1つのコマンドにしよう。シェルスクリプトだ
- シェルスクリプトのファイルを作る。名前をsample.shにしよう。
- $1などは、シェルスクリプトの引数。つまり、コマンドのオプション
#!/bin/sh
echo -n $1 $2 $3 $4
./mt-search $1 $2 $3 $4 | python count.py
- パーミッションを変えよう。
- 実行して!
4. コマンド実行をもっと一度にまとめてやらせたい。さらにシェルスクリプトにしよう。(各探索で d における最悪のNode g は、事前に求めておくこと)
- たとえば、bを変化させた場合の深さ優先探索の計測には、以下のようなファイルを作る sample0.sh
- (emacsの1行コピーは、control kとcontrol y。 行の先頭に移動してControl kでバッファー、Control yで貼り付け)
#!/bin/sh
./sample.sh 2 4 15 0
./sample.sh 4 4 85 0
./sample.sh 6 4 259 0
./sample.sh 8 4 585 0
./sample.sh 10 4 1111 0
- パーミッションを変えよう。
- 実行しよう!
- 実行結果ファイルに残そう。たとえば、bに関する深さ優先探索の結果だから、ファイル名をb0とすると
5. bの幅優先探索、bの反復進化探索についても、計測しよう。4のシェルスクリプトをコピーして、内容を変更して実行しよう
- sample0.shを名前を変えてコピーしよう
- cp sample0.sh sample1.sh (中身をemacs で編集する)
- パーミッションを変えよう。
- 実行しよう!
- ファイルに!
6. Windowsへ情報を移そう。
- Tera Termを使って、ファイルの内容をカットアンドペースト
- Power shellから ssh作戦でもよいし、scpでもいい
7. bに関する計測結果を、MaNaBo フォーラムに報告して、確認しよう。(今日の課題)
8. ここから先は、各自。gnuplot、エクセルなど、お任せします。
この実験で小笠原先生が計測を指示した、b,m.dの組。ただし、dは、両端のゴールを計算して、計測結果の悪い方を採用(上の例を参考に)
2 4 4
4 4 4
6 4 4
8 4 4
10 4 4
b0, b1, b2 (b、つまり、枝の数の効果。dが木の一番深いところなので、各探索の最悪のゴール(最後に見つけるゴール)にあたる)
2 2 2
2 4 2
2 6 2
2 8 2
2 10 2
m0, m1, m2 (m、つまり、木の深さの効果。dは浅いところ2が指定されている)
2 10 2
2 10 4
2 10 6
2 10 8
2 10 10
d0, d1, d2 (d、ゴールの深さ。各dの最悪のノードの場合を計測しよう。最初は浅いところ、最後は葉にあたる)
コメントをはずして実行してみると、よい。
import fileinput
import re
lines = 0;
nodes = 0;
for line in fileinput.input():
if(re.match("->", line) or re.search("Open",line)):
line = line.split("->")
# print(line,end=" : ")
elm = len(line) - 2
# print(elm, end="\n")
lines += 1
if(elm > nodes):
nodes = elm
print(lines,nodes)